
PDF化までは標準的な環境でも「PDFで印刷」で対応できます。
PDFで貰った資料に、WORD文書をPDF化して、あとはこれを結合したいんだけどな、というシーンはないでしょうか。
有料ツールが利用できる環境ならであれば特に問題ないでしょう。
フリーのツールでどうにかしているけど、これ自分で作ってしまえばもっと融通が利くのにな、と思ったことはありませんか?
そんな方向けに、PythonでPDFを編集できるライブラリ「PyPDF」をご紹介したいと思います。
具体的には、次についてのサンプルコードをご紹介します。
・PDFの分解
・PDFの結合
・PDFからテキスト抽出
・PDFから画像抽出
それでは、詳しく見ていきましょう!
PyPDFバージョンちがいについて
今回、私も調べていたのですが、PyPDFはバージョンがとてもややこしいです。
PyPDFからpyPDF2と移り、その後PyPDF4というモジュールもリリースされたようですが、メインストリームとしてはPyPDF2が使われていたようです。
その後、2023年6月時点の最新としてはPyPDFに戻ったようです。
モジュールを使う側としては、次を気を付ける必要があります。
・インストールするモジュールの変更
・関数の変更
実際に、参考にしたサンプルコードでは関数が古く、エラーになったりがありました。
エラーコード内で、「instead of ~」のように、関数名を変更するよう示唆がありました。
今回、執筆にあたって使ったバージョンは次の通りです。
・Pypdf 3.9.1
不具合などありましたら、モジュールの種類とバージョンに気を付けてみてください。
PyPDFのインストール
まずはモジュールのインストールからです。
普通の手順でインストールできます。
pip install PyPDF先述のバージョンちがいで動作が怪しそうであれば、
次のようにバージョンを指定してインストールします。
pip install PyPDF==3.9.1PyPDFのバージョン確認方法
先述のとおり、PyPDFにはモジュール名やバージョンで仕様が異なります。
次の方法でバージョンを確認できます。。
import pypdf
#動作確認したモジュールのバージョン:pypdf 3.9.1
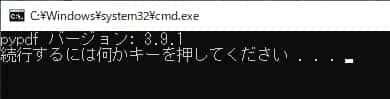
# モジュールのバージョン
print(f"{pypdf.__name__} バージョン: {pypdf.__version__}")このようにモジュールのバージョンが表示されます。
PDFの分解
ここからは具体的な使い方をご紹介していきたいと思います。
まずはPDFの分解からです。
PDF読み込み
次のようにしてPDFを読み込みます。
import pypdf
# 読み込みPDFを指定
reader = pypdf.PdfReader("sorce.pdf")PDFページ数の取得
PDFは複数ページの場合が多いです。総ページ数を取得します。
import pypdf
# PDFページ数の取得
total_pages = len(reader.pages)
print(f"total_pages= {total_pages}")PDFの分割
PDFを分割する関数そのものはありません。
先で何となくわかるかもしれませんが、ページを指定して個別のPDFファイルとして保存します。
次の例では「sourcepage = reader.pages[n]」でn番目のページをソースに指定しています。
「writer = pypdf.PdfWriter()」で書き込み用の関数を呼び出し、ファイル出力させています。
import pypdf
sourcepage = reader.pages[n]
#pdf = reader.pages[0]
writer = pypdf.PdfWriter()
writer.add_page(sourcepage)
with open(f"{path}p{n}.pdf", "wb") as fp:
writer.write(fp)
writer.close()サンプルコード
これらを合体し、nページのPDFサンプルを、ページ個別にPDFファイル分割するサンプルがこちらです。
import pypdf
import os
#動作確認したモジュールのバージョン:pypdf 3.9.1
# モジュールのバージョン
print(f"{pypdf.__name__} バージョン: {pypdf.__version__}")
# 読み込みPDFを指定
reader = pypdf.PdfReader("sorce.pdf")
# PDFページ数の取得
total_pages = len(reader.pages)
print(f"total_pages= {total_pages}")
# 保存ディレクトリ作成
path = "./splited/"
if not os.path.exists(path):
os.makedirs(path)
# PDFをページごとに分割
for n in range(total_pages):
sourcepage = reader.pages[n]
#pdf = reader.pages[0]
writer = pypdf.PdfWriter()
writer.add_page(sourcepage)
with open(f"{path}p{n}.pdf", "wb") as fp:
writer.write(fp)
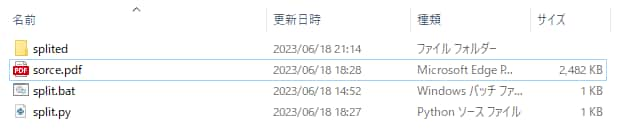
writer.close()実行結果がこちらです。
下記のフォルダ構成になっています。
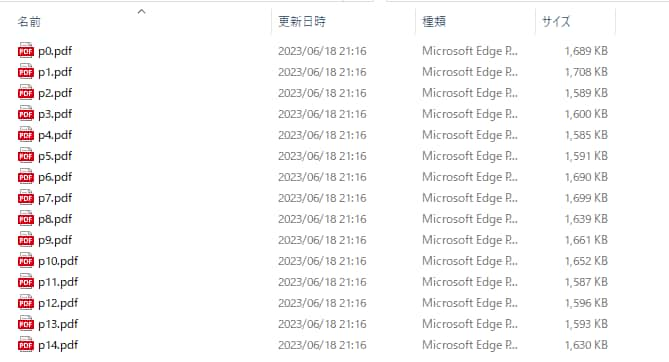
「splited」フォルダの中には、下記のようにページごとに分割したPDFファイルが作成されます。
PDFの結合
PDFの結合は、実は分割とそう変わりません。
各ページごとに出力していたのを、すべてappendしてからファイル出力するだけです。
ということで、いきなりサンプルコードをみてみましょう!
サンプルコード
同じディレクトリに置いた「input1.pdf」、「input2.pdf」、「input3.pdf」を結合して、
「output.pdf」として出力します。
import pypdf
#動作確認したモジュールのバージョン:pypdf 3.9.1
# モジュールのバージョン
print(f"{pypdf.__name__} バージョン: {pypdf.__version__}")
def merge_pdfs(input_paths, output_path):
writer = pypdf.PdfWriter()
for input_path in input_paths:
print(input_path)
writer.append(input_path)
writer.write(output_path)
writer.close()
# マージしたいPDFリスト
pdf_lists = ["input1.pdf", "input2.pdf", "input3.pdf"]
# マージ
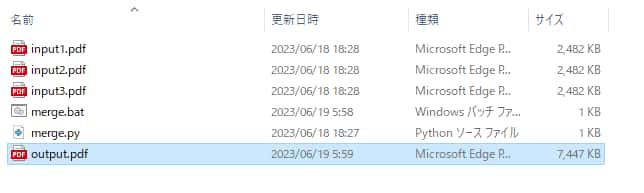
merge_pdfs(pdf_lists, "output.pdf")batから実行した結果がこちらです。
無事「output.pdf」を出力できました。ファイルサイズでもちゃんと「input1.pdf」~「input3.pdf」を結合したサイズになっています。
PDFからテキスト抽出
次はPDFからテキスト抽出してみたいと思います。
結合のところでやった内容がほとんどです。
変わるのは次の部分です。
import pypdf
# PDFファイルの読み込み
reader = pypdf.PdfReader("sorce.pdf")
# テキスト抽出
pdf = reader.pages[page]
text = pdf.extract_text()
print(text)pdfをページ指定で読み込み、「extract_text()」でテキスト出力します。
サンプルコード
同様にいきなりサンプルコードを見てみましょう。
PDF内の全ページのテキストを抽出し、出力したいと思います。
import pypdf
#動作確認したモジュールのバージョン:pypdf 3.9.1
# モジュールのバージョン
print(f"{pypdf.__name__} バージョン: {pypdf.__version__}")
# PDFファイルの読み込み
reader = pypdf.PdfReader("sorce.pdf")
# PDFページ数の取得
total_pages = len(reader.pages)
all_text = ""
# ページ内のテキスト取得
for page in range(total_pages):
pdf = reader.pages[page]
text = pdf.extract_text()
print(text)
all_text += text batから実行した結果がこちらです。
無事、テキストを取得することができました。
今回、練習サンプルに使った資料はこちらです。SDGsに関する公開資料です。
持続可能な開発目標(SDGs)
指標仮訳 PDF版 最終更新日:2021年6月
PDFから画像抽出
最後に画像抽出をやってみたいと思います。
こちらも実はページ取得時にできていまして、取得したものを取り出すだけです。
「reader.pages[page]」で取得したページに対して、「page.images」に画像リストが格納されています。
下記のようにして、ファイル出力すると取り出せます。
import pypdf
# PDFの読み込み
reader = pypdf.PdfReader("sorce.pdf")
# ページの取得
page = reader.pages[page]
# ページ内の全画像出力
for image_file_object in page.images:
filename = f"{path}{str(count)}_{image_file_object.name}"
print(filename)
with open(filename, "wb") as fp:
fp.write(image_file_object.data)
count += 1サンプルコード
ひと手間掛けて、PDF内の全ページについて画像抽出してみます。
サンプルコードがこちらです。
import pypdf
import os
#動作確認したモジュールのバージョン:pypdf 3.9.1
# モジュールのバージョン
print(f"{pypdf.__name__} バージョン: {pypdf.__version__}")
# PDFの読み込み
reader = pypdf.PdfReader("sorce.pdf")
# PDFページ数の取得
total_pages = len(reader.pages)
count = 0
for page in range(total_pages):
# ページの取得
page = reader.pages[page]
# 保存ディレクトリ作成
path = "./img/"
if not os.path.exists(path):
os.makedirs(path)
# ページ内の全画像出力
for image_file_object in page.images:
filename = f"{path}{str(count)}_{image_file_object.name}"
print(filename)
with open(filename, "wb") as fp:
fp.write(image_file_object.data)
count += 1bat実行すると、次のようになります。
練習サンプルに使った資料は、同じくSDGsに関する公開資料を使いました。
無事、画像抽出できました。

以上になります。
どの「PyPDF」を使うか?で躓かなければ、適切なサンプルコードが見つかると思います。
何か動かない。。。でハマることもないと思います。
もし、うまくいかないようでしたら、冒頭にも述べましたが、PyPDFの種類、バージョンをよくご確認ください。
くどいようですが、今回使用させて頂いたのはこちらのモジュールでした。
・Pypdf 3.9.1
この記事が少しでもお役に立てれば幸いです。
それでは、読んで頂きありがとうございました!