
ワードクラウドを利用したことはありますでしょうか?
Pythonモジュールを利用すると意外と簡単に自分でもWord Cloudプログラムを作ることができます。
日本語フォント表示するところまでをご紹介したいと思います。
やること
・必要モジュールのインストール
・テキスト読み込み
・ワードクラウド生成
・表示
・日本語フォント対応
それでは順に見ていきましょう!
ワードクラウドとは?
まず、そもそものところに触れておきたいと思います。
ワードクラウドは、テキストデータの視覚化手法の一つです。
大量のテキストデータから有用な情報やパターンを抽出するテキストマイニングのひとつです。
ワードクラウドは、テキストデータ内の単語の出現頻度を可視化する際に用いられます。
頻出する単語ほど大きく表示され、出現頻度が低い単語ほど小さくなります。
この視覚的な表現は、テキストの主要なトピックやテーマを把握するのに役立ちます。
ワードクラウドは情報の要約や比較、トレンドの分析などに利用され、文章全体の雰囲気をつかむ手助けとなります。ただし、単語の出現頻度のみを考慮するため、文脈や意味は無視されることがあります。
そのため、正確な情報把握のためには他の分析手法と組み合わせることが重要です。
ワードクラウド生成ツールは多数存在し、カスタマイズも可能です。
デザインや色、単語の重み付け方法を調整して、視覚的な表現をカスタムすることができます。
ワードクラウドを利用する手段としては色々あり、Word Cloud for Google Chromeというものもあります。
同じ機能をPythonプログラムで実現してみたいと思います。
やること
必要モジュールのインストール
今回、必要になるモジュールは次の2つです。
pipなどを利用してモジュールをインストールします。
pip wordcloud
pip matplotlibテキスト読み込み
ワードクラウドはテキストデータ内の単語の出現頻度を可視化します。
それなりのボリュームが必要になります。
今回は、青空文庫の公開テキストデータを利用してみたいと思います。
青空文庫
https://www.aozora.gr.jp/
青空文庫-銀河鉄道の夜(宮沢賢治)
https://www.aozora.gr.jp/cards/000081/files/456_15050.html
text_sample.txtファイルを作成し、全文をコピーしておきます。
次のようにして、テキストファイルのデータを取得させます。
file_path = "text_sample.txt"
with open(file_path, 'r', encoding='utf-8') as file:
text_data = file.read()テキストの読み込みは、特に追加モジュールは必要ありません。
ワードクラウド生成
今回のメインですね!
といっても全然やることはありません。
from wordcloud import WordCloud
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text_data)先ほど取得したテキストデータを引数にして、関数実行するだけです。
この時点では視覚的には何も分からない状態です。
次は可視化モジュールを使って表示したいと思います。
グラフで可視化
Matplotlibは、Pythonのデータ可視化ライブラリです。
グラフやチャートの作成に利用されます。
折れ線グラフ、ヒストグラム、散布図など幅広いプロットをサポートし、カスタマイズ性が高く、科学やデータ分析、報告などで広く使用されています。
Matplotlibを使って先ほど作成したwordcloudデータを可視化していきましょう。
import matplotlib.pyplot as plt
# プロット設定
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()先ほど作成したwordcloudを引数にして、グラフ設定をします。
最後に「plt.show()」で表示します。
ここまでのコードを組み合わせて実行してみます。
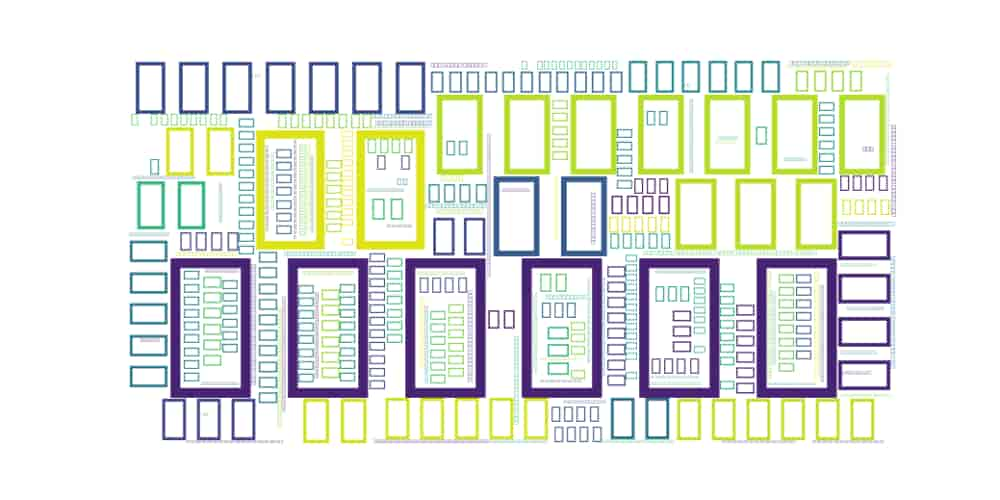
なんじゃこりゃ!ですよね。
これは日本語フォント設定ができていないため、文字化けしています。
ということで、次は日本語フォント対応をしていきます。
日本語フォント対応
今回はMeiryoフォントを設定します。
WordCloudオブジェクトを生成する際に、font_path設定を追加します。
font_path設定に、matplotlib.font_managerというものを利用します。
from matplotlib.font_manager import FontProperties
font_path = "C:/Windows/Fonts/meiryo.ttc" # Meiryoフォントファイルのパスを指定
font_prop = FontProperties(fname=font_path)
# WordCloudオブジェクトを作成し、日本語フォントを指定
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(text_data)これで日本語フォントに対応して表示できるようになります。
上記はWindows環境の例です。
他のOSでは、”C:/Windows/Fonts/meiryo.ttc”を適宜変更ください。
サンプルコード
ここまでのコードを組み合わせたサンプルコードがこちらになります。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from matplotlib.font_manager import FontProperties
def generate_wordcloud(text_data, font_path):
# フォントプロパティを作成
font_prop = FontProperties(fname=font_path)
# WordCloudオブジェクトを作成し、日本語フォントを指定
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(text_data)
# プロット設定
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
if __name__ == "__main__":
# ワードクラウドに表示したいテキストデータを用意
file_path = "text_sample.txt"
with open(file_path, 'r', encoding='utf-8') as file:
text_data = file.read()
font_path = "C:/Windows/Fonts/meiryo.ttc" # Meiryoフォントファイルのパスを指定
generate_wordcloud(text_data, font_path)実行結果がこちらです。

「ジョバンニ」と「カムパネルラ」が主な登場人物なんだろうな。
「銀河ステーション」というのも重要なキーワードっぽい!
といった連想ができそうですね!
テキストデータ内で頻出する単語を大きく表示し、テキストの主要なトピックやテーマを把握する、
というのがワードクラウドの狙いです。
たしかに狙い通りに役立ちそうです。
お手持ちのテキストデータの分析に試してみてはいかがでしょうか。
今回は以上となります。
本記事が少しでもお役に立てれば幸いです。
それでは、読んで頂きありがとうございました!