
OCRってどうやっているんだろう?でも敷居が高そうと思っていませんか?
Googleが開発したオープンソースのOCRエンジン「Tesseract」を使うと、簡単に文字認識することができます。
やること
・Tesseractのインストール
・pytesseractモジュールのインストール
・画像を読み込む
・画像を加工(拡大, 二値化)
・文字認識
今回は事前準備がありますが、手順がはっきりしていれば何てことはありません。
それでは順番に見ていきましょう!
順番にみていく
Tesseractのインストール
まずOCRエンジンとライブラリのインストールが必要です。
Tesseractをインストールしましょう。
Windows環境の場合と、ラズパイ環境の場合の2パターンをご紹介します。
Windows環境の場合
Github内のTesseractのページからインストーラと言語データをダウンロードします。
最後に環境パスを設定します。
順に説明していきます。

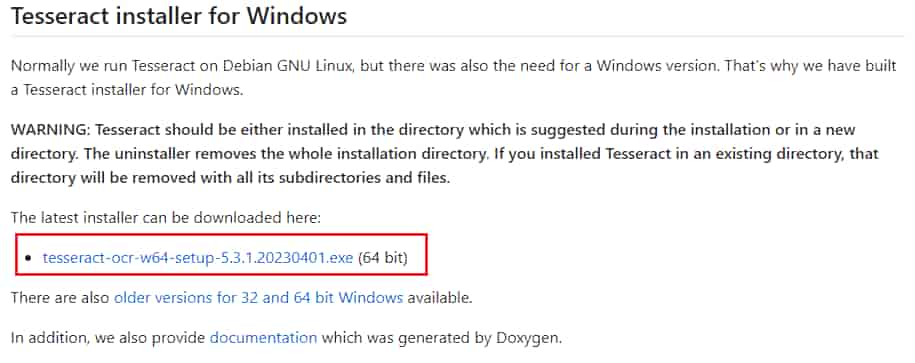
インストーラはこちらに格納されています。
次の形式でネーミングされたファイルです。(XXXはバージョン)
tesseract-ocr-w64-setup-XXX.exe (64 bit)
次に言語データを入手します。
こちらのページから該当の言語データを探してダウンロードします。
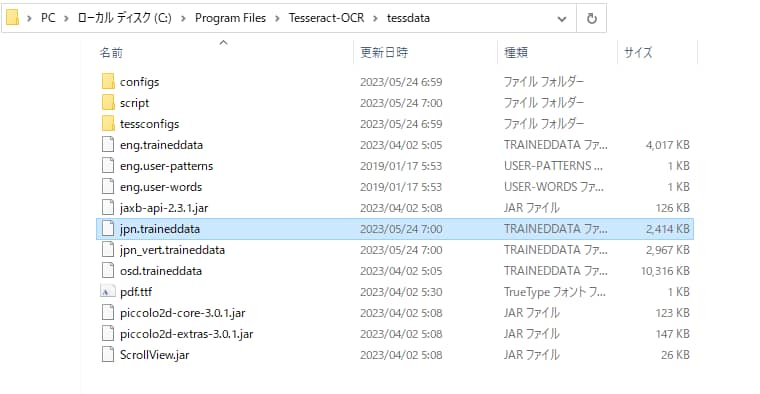
今回は日本語の言語データ「jpn.traineddata」を選びました。

ダウンロードした言語データはTesseract-OCRのインストールフォルダ内にある「tessdata」フォルダに置きます。
最後に環境変数を設定します。
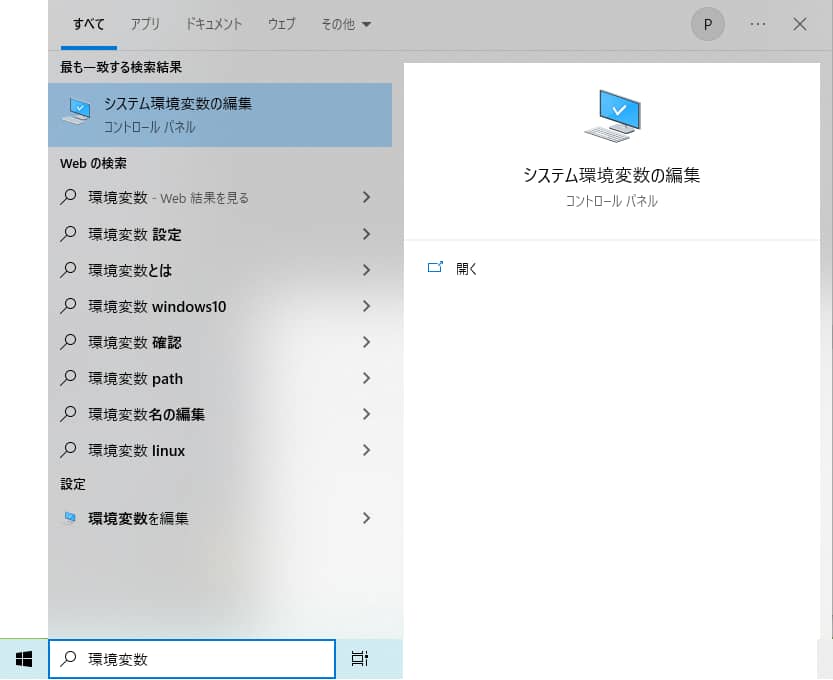
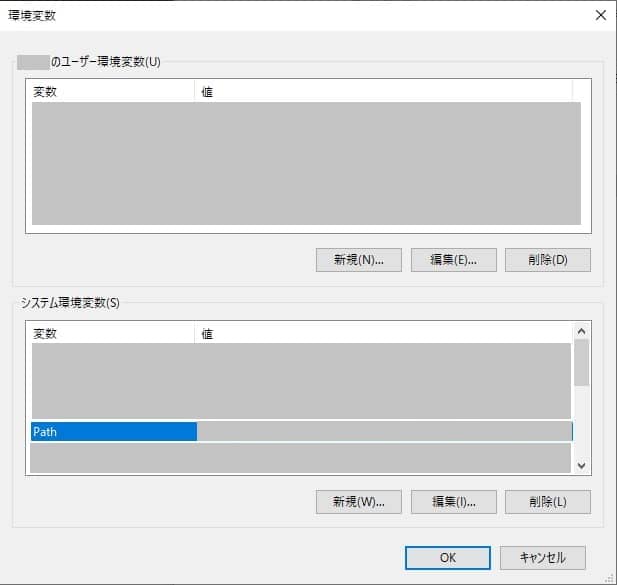
Windowsロゴ横の検索ウィンドウから「環境変数」で検索します。
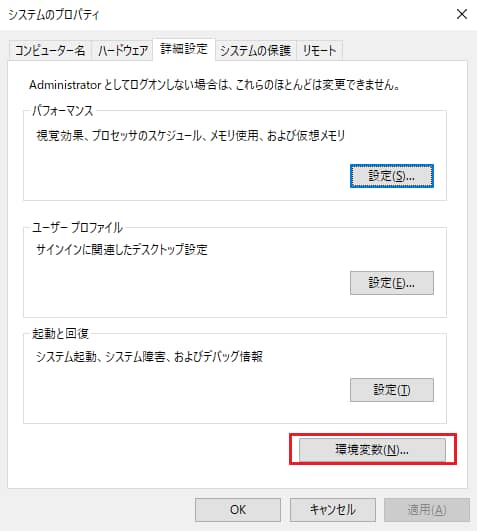
システムのプロパティ画面から環境変数を選択します。
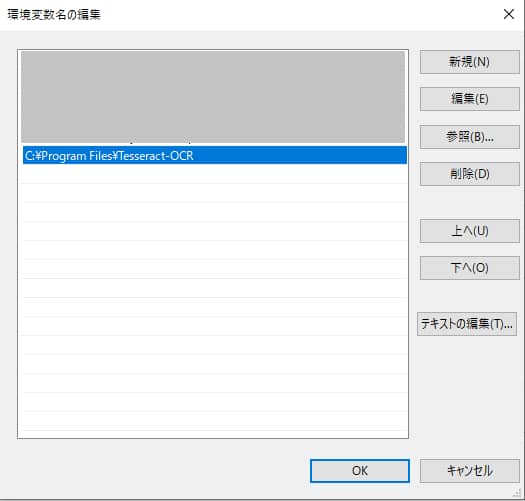
環境変数のプロパティ画面からシステム環境変数のPathを編集し、Tesseractのインストールパスを追加します。
Tesseractのインストールパスのデフォルトは「C:\Program Files\Tesseract-OCR」です。
これでWindows環境の場合の準備は完了です。
Linux(ラズパイdebian, ubuntu 22.04 LTS環境などの場合)
Linuxの場合はもう少し簡単です。
少なくともラズパイdebian、ubuntu 22.04LTS環境で動作確認できています。
ターミナルを開き、次を順番に実行します。
sudo apt-get update
sudo apt-get install tesseract-ocr
sudo apt-get install libtesseract-dev
sudo apt-get install tesseract-ocr-jpn他の言語データをインストールしたい場合はtesseract-ocr-(language_code)を使用します。
たとえば、英語の場合はsudo apt-get install tesseract-ocr-engとなります。
次に、TesseractをPythonから呼び出すために、環境変数TESSDATA_PREFIXを設定する必要があります。
以下の手順で設定します。
ユーザのホームディレクトリにある.bashrcファイルを開きます。
nano ~/.bashrcファイルの最後に、次の行を追加します。
export TESSDATA_PREFIX=/usr/share/tesseract-ocr/4.00/tessdata/ターミナルで以下のコマンドを実行し、環境変数を有効にします。
source ~/.bashrcこれでラズパイ環境の場合の準備は完了です
pytesseractモジュールのインストール
ここからは共通の手順です。
TesseractをPythonで実行するためのモジュールとして、pytesseractをインストールします。
pip install pytesseract画像を読み込む
ここからはpythonプログラムで順に解説していきます。
今回の動作環境の想定は次です。
実行ファイルと同じ階層に「target.png」ファイルがあります。
この画像をOCRするとします。
テスト環境はWindowsです。
「target.png」は次の画像です。OCRの検索ボリューム数です。
この中から数値を抜き出してOCRしたいと思います。
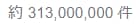
まずは画像の読み込みです。
今回はPILを使いました。
from PIL import Image
image_path = "target.png"
path_image = (image_path)
image = Image.open(path_image)画像を加工(拡大, 二値化)
OCRしやすくするため、画像を拡大して二値化します。
後で利用しやすいように関数化しておきます。
from PIL import Image
def image_processing(image_path, mag):
# 拡大処理
path_image = (image_path)
image = Image.open(path_image)
resized_image = image.resize((image.width * mag, image.height * mag), resample=Image.BICUBIC)
# # 二値化処理
thresh = 180
max = 255
binary_image = resized_image.convert('L')#グレースケール変換
binary_image = binary_image.point(lambda x: 0 if x < thresh else max, '1')
# binary_image.save('img/target_after.png')
binary_image.save('target_after.png')
return binary_image
# 画像を読み込む
image_path = "target.png"
image = Image.open(image_path)
# 画像を加工する
image = image_processing(image_path, 2)文字認識
いよいよ文字認識させてみます。
画像の読み込み部分は省略しています。
まずはOCR部分だけ切り取って見てみましょう。
import pytesseract
from PIL import Image
command = '-l jpn --psm 7 -c tessedit_char_whitelist="0123456789"'
image = image_processing(image_path, 2)
text = pytesseract.image_to_string(image, config=command)こんな感じになります。
commandで指定しているのは認識オプションです。
この例では、日本語、1列の文字数字として扱う、0~9の数字として扱うオプションです。
実際にやってみると分かりますが、コンマなどが結構邪魔になります。
そこで、正規表現を使ってもっと明示的に数値だけを抽出しています。
import pytesseract
from PIL import Image
import re
# OCRを実行する
command = '-l jpn --psm 7 -c tessedit_char_whitelist="0123456789"'
image = image_processing(image_path, 2)
text = pytesseract.image_to_string(image, config=command)
numbers = re.findall(r'\d+', text)
combined_numbers = int(''.join(numbers))サンプルコード
これらを合体したサンプルコードは次の通りです。
windowsバッチファイルにして実行すると次のようになります。
無事、数字だけを抽出することができました。
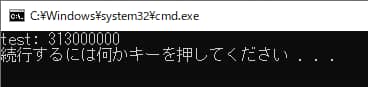
import pytesseract
from PIL import Image
from collections import Counter
import re
def image_processing(image_path, mag):
# 拡大処理
path_image = (image_path)
image = Image.open(path_image)
resized_image = image.resize((image.width * mag, image.height * mag), resample=Image.BICUBIC)
# # 二値化処理
thresh = 180
max = 255
binary_image = resized_image.convert('L')#グレースケール変換
binary_image = binary_image.point(lambda x: 0 if x < thresh else max, '1')
# binary_image.save('img/target_after.png')
binary_image.save('target_after.png')
return binary_image
def run():
# OCRを実行する画像ファイルのパス
# image_path = "./img/target.png"
image_path = "target.png"
# 画像を読み込む
image = Image.open(image_path)
# OCRを実行する
text_lists = []
command = '-l jpn --psm 6 -c tessedit_char_whitelist="0123456789"'
image = image_processing(image_path, 2)
text = pytesseract.image_to_string(image, config=command)
numbers = re.findall(r'\d+', text)
combined_numbers = int(''.join(numbers))
return combined_numbers
if __name__ == '__main__':
# print("test")
print(f"test: {run()}")おまけ
Tesseractの主なオプション一覧を示します。
詳細はヘルプメッセージを参照するか、Tesseractの公式ドキュメントをご覧ください。
--helpまたは-h: Tesseractのヘルプメッセージを表示します。
--versionまたは-v: Tesseractのバージョン情報を表示します。
--tessdata-dir <directory>: カスタムの言語データ(.traineddataファイル)が格納されているディレクトリを指定します。
--list-langs: 使用可能な言語を一覧表示します。
--psm <mode>: ページセグメンテーションモードを指定します。主なオプションは以下の通りです:
3: Fully automatic page segmentation, but no OSD. (Default)
完全に自動でページを分割しますが、OSD はありません。(デフォルト)
6: Assume a single uniform block of text.
単一の均一なテキストブロックを想定
実際にOCRに使えるコマンド例(サンプルコードベース)
#日本語
command = '-l jpn'
#英語
command = '-l eng'
#日本語と英語
command = '-l eng+jpn'
#日本語で単一のテキストブロック想定
command = '-l jpn --psm 6'
以上となります。
少しでもお役に立てれば幸いです。
それでは、読んで頂きありがとうございました!